Fiber is built around three main concepts:
- Accounts represent third-party accounts belonging to your users,
- Destinations are where Fiber writes data, and
- Syncs move a particular type of data from accounts to destinations
Let's dig deeper using the example below:
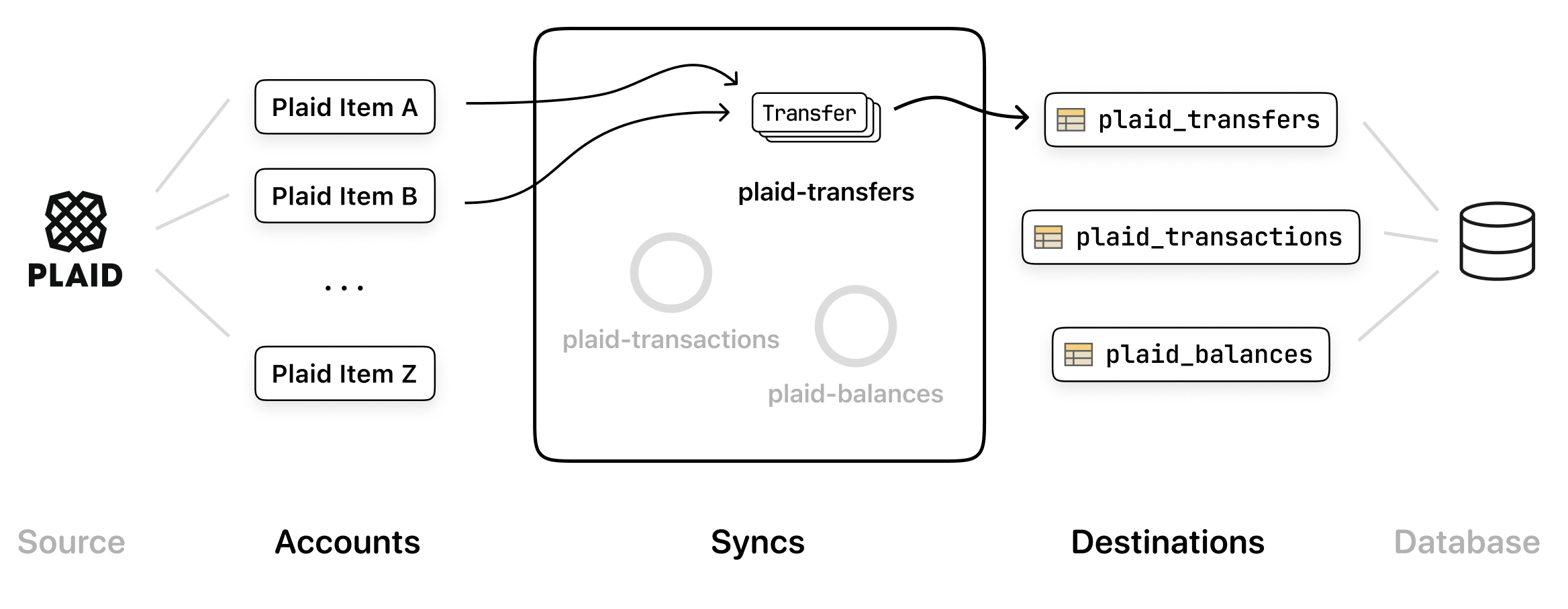
An example Plaid integration using Fiber
Plaid is a popular universal API for accessing your
customers' banking information. In the setup above, we're using Fiber to sync
Transfer objects from a set
of Plaid accounts into a destination table called PlaidTransfers, living
inside a Postgres database.
Accounts map to a particular third-party resource
Notice that each account in the diagram corresponds to a Plaid Item, not to a Plaid Account. For each source API, Fiber selects the most appropriate third-party resource to represent a Fiber account. So every Plaid account in Fiber corresponds to a Plaid Item. Every Shopify account in Fiber corresponds to a Shopify Shop. Every Xero account in Fiber corresponds to a Xero Tenant. And so on.
Check out our source catalog to learn what to expect from each source.
Syncs read from a subset of accounts
The plaid-transfers sync is reading from the first two accounts, Item A
and Item B, but not the last one, Item Z. Each sync pulls from a
subset of accounts of a particular source API, which may include all of them
or just a few. This flexibility is useful for gradually rolling out integration
features or making them available to a premium subset of users.
You can name syncs whatever you want, but we recommend following the pattern
source-type-sync-type, like the example above. Names must be unique within an
environment.
Syncs write data into one or more destinations
The plaid-transfers sync writes data into the PlaidTransfers destination,
which is a table inside of a database (eg. Postgres). Destinations in Fiber are
database tables or folders inside of cloud storage buckets that receive
third-party data.
Syncs typically write into a single destination, but there are exceptions.
Certain sync types can produce data of different schemas, and therefore write
into multiple destinations. For instance, a sync of type "Shopify Products" can
write into two destinations, one for
Product rows
and another for
ProductVariant
rows.
Destinations follow the schema of the source API
Fiber maps the data from the source API to the destination schema in an
intuitive way. For example, according to the Plaid API, a Transfer object
contains the following fields:
// Schema of Plaid Transfer
{
id: string
created: string
account_id: string
ach_class: string
amount: string
cancellable: boolean
description: string
authorization_id: string
network: string
network_trace_id: string | null
metadata: {
key1: string
key2: string
}
// ... others
}Fiber translates this schema into the following DDL for the Postgres table PlaidTransfers:
CREATE TABLE "PlaidTransfers" (
id text NOT NULL,
created_at timestamp with time zone,
plaid_account_id text,
ach_class text,
amount double precision,
cancellable boolean,
description text,
authorization_id text,
network text,
network_trace_id text,
metadata jsonb,
-- ... others
-- meta columns
account_id text,
pf_id uuid DEFAULT gen_random_uuid() UNIQUE,
pf_created_at timestamp with time zone,
pf_updated_at timestamp with time zone,
-- primary key
CONSTRAINT plaidtransaction_id_account_id_unique UNIQUE (id, account_id),
);There are a few things to note about this translation. First, on top of the fields from the source API, Fiber adds a handful of "meta columns" to the destination schema:
account_id- The ID of the Fiber account associated with this row.pf_id- A unique ID automatically generated for each row.pf_created_at- The timestamp when the row was created by Fiber.pf_updated_at- The timestamp when the row was last updated by Fiber.
The original Transfer object from Plaid already has an account_id field, so
Fiber maps it to the plaid_account_id column in the destination. Each sync
type handles these naming conflicts differently, so be sure to check the
specific source documentation for details.
The pf_id serves as the primary key for the table, rather than the id field
from the Transfer object. But the latter is part of a constraint
(Transfer.id, account_id), which ensures that only one row with a particular
id can exist for each account.